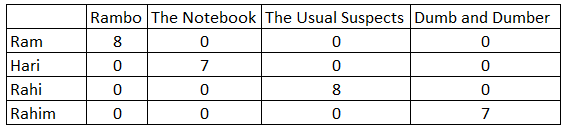
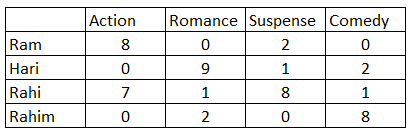
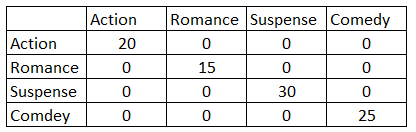
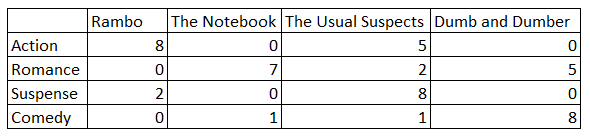
In [71]:
# Plotting distributions of ratings for 329 interactions with movieid 356
# Let us fix the size of the figure
plt.figure(figsize = (7, 7))
rating[rating['movieId'] == 356]['rating'].value_counts().plot(kind = 'bar')
# This gives a label to the variable on the x-axis
plt.xlabel('Rating')
# This gives a label to the variable on the y-axis
plt.ylabel('Count')
# This displays the plot
plt.show()